适读人群:希望用 AI Agent 完成真实软件工程任务的开发者和架构师。
0. 两个震撼的真实实验
实验一:Anthropic 的受控对照实验
Anthropic 的工程师用 Claude Sonnet 4.5 做了一组对照实验,相同的模型、相同的任务(构建一个可运行的游戏),只改变 Harness 配置:
| 条件 | 耗时 | 花费 | 结果 |
|---|---|---|---|
| 无 Harness(单 Agent) | 短 | $9 | 核心玩法功能不可运行(物理引擎接线断裂,输入无响应) |
| 完整 Harness(planner + generator + evaluator) | 6 小时 | $200 | 游戏可以实际运行,16个功能完整实现 |
模型没有变,Harness 变了。差距超过 20 倍。
实验二:OpenAI 的五个月生产实践
OpenAI 内部有一个三人工程师团队,用五个月时间构建了一款有真实用户的内部产品,设立了一条铁律:没有一行代码由人类编写。
五个月后:
- 代码库约 100 万行代码
- 约 1,500 个 PR 被打开并合并
- 平均每位工程师每天处理 3.5 个 PR(随团队扩展到 7 人后吞吐量还在增长)
- 产品已有数百名内测用户,包括每日活跃的深度用户
他们的结论是:
“工程师的工作从编写代码,转变为设计环境、明确意图、构建反馈回路。”
这两个实验共同指向同一个结论:模型提供能力,Harness 提供可靠性。
1. 什么是 Harness Engineering?
1.1 核心定义
为 AI Agent 构建的、用于指导、约束、验证和延续其工作的完整运行环境。
“Harness”原意是”马具”或”安全带”——它本身不产生动力,但让力量得以被安全、可控地使用。
在软件工程中,test harness(测试框架)早已是成熟概念:包裹待测代码的基础设施,负责初始化环境、提供数据、收集结果。Harness Engineering 将这一思想延伸到 AI Agent 的整个工作流。
1.2 直观类比:赛车工程团队
| 赛车要素 | AI Agent 对应 |
|---|---|
| 驾驶员技术 | 模型能力(Claude / GPT 的智能水平) |
| 赛前策略简报 | Instructions(AGENTS.md、架构文档) |
| 实时遥测数据 | State(progress.md、feature_list) |
| 进站检验 | Verification(测试、lint、E2E) |
| 明确的圈次目标 | Scope(一次一个功能) |
| 赛后技术分析 | Session Lifecycle(handoff、clean-state) |
没有工程团队,顶级驾驶员也会跑偏、跑没油、跑完不知道发生了什么。

1.3 Harness 五大子系统关系图
graph TB
subgraph Harness[AI Agent Harness]
A[Instructions
指令层] --> B[State
状态层]
B --> C[Verification
验证层]
C --> D[Scope
范围层]
D --> E[Session Lifecycle
生命周期层]
E --> A
end
F[AI Agent] --> Harness
Harness --> G[可靠输出]
style Harness fill:#e1f5ff
style A fill:#4dabf7
style B fill:#51cf66
style C fill:#fcc419
style D fill:#ff6b6b
style E fill:#a760ff
style F fill:#868e96
style G fill:#40c057
2. AI Agent 在真实任务上失败的三大根源
graph LR
A[AI Agent 失败根源] --> B[上下文遗忘
Context Loss]
A --> C[验证差距
Verification Gap]
A --> D[越界失控
Overreach]
B --> B1[重新实现已完成功能]
B --> B2[错误积累]
C --> C1[完成偏见]
C --> C2[自我评估偏差]
D --> D1[范围蔓延]
D --> D2[70% 完成度陷阱]
style A fill:#ff6b6b
style B fill:#fcc419
style C fill:#fcc419
style D fill:#fcc419
style B1 fill:#ffe3e3
style B2 fill:#ffe3e3
style C1 fill:#ffe3e3
style C2 fill:#ffe3e3
style D1 fill:#ffe3e3
style D2 fill:#ffe3e3
2.1 上下文遗忘(Context Loss)
AI 模型没有跨会话的持久记忆,上下文窗口有限且会清零。一个需要 6 小时完成的任务,如果没有状态持久化:
- Agent 会重新实现已完成的功能
- 不知道哪些部分处于损坏状态
- 在”模糊记忆”的基础上做决策,产生错误积累
Anthropic 的工程师还发现了一个更微妙的问题——**”上下文焦虑”(Context Anxiety)**:
当模型接近它认为的上下文限制时,会开始提前收尾工作,草草了事,即便实际上还有足够的空间。Claude Sonnet 4.5 表现出这一倾向,单靠压缩(Compaction)不足以解决,必须通过”上下文重置(Context Reset)”——清空上下文并用结构化交接文档重新启动——才能解决。
2.2 验证差距(Verification Gap)
Agent 有强烈的”完成偏见”——它倾向于相信自己写的代码是正确的:
“当被要求评估自己的工作时,Agent 倾向于自信地称赞它——即使在人类观察者看来质量明显平庸。”
—— Anthropic 工程博客
在 Anthropic 的早期实验中,评估 Agent 会发现合法的问题,然后自我说服认为”其实没那么严重”,最终批准了有缺陷的工作。这不是模型缺陷,而是在没有外部验证机制时的系统性偏差。
2.3 越界失控(Overreach)与范围蔓延
没有明确的 Scope 约束,Agent 会:
- 修复 bug A 时顺手重构模块 B
- 实现功能 X 时预先为功能 Y 搭骨架
- 最终每个功能都 70% 完成,没有一个完全可用
OpenAI 的团队描述为:当环境规范不够明确时,Agent 缺乏实现高级目标所需的工具、抽象层和内部结构,无法取得可靠进展。
解决方案从来不是”让它再努力一点”,而是追问:”还需要什么样的能力,如何让它对 Agent 既清晰可读又可强制执行?”
3. Harness 的五大子系统
Harness 由五层构成,每层解决一类核心问题:
graph TD
subgraph Harness[Harness 五大子系统]
A[Instructions
指令层] --> B[State
状态层]
B --> C[Verification
验证层]
C --> D[Scope
范围层]
D --> E[Session Lifecycle
生命周期层]
end
subgraph A_Details[ ]
A1["AGENTS.md
ARCHITECTURE.md
SECURITY.md"]
end
A --- A1
subgraph B_Details[ ]
B1["progress.md
feature_list.json
session-handoff.md"]
end
B --- B1
subgraph C_Details[ ]
C1["单元测试/类型检查/Lint
Playwright E2E
Sprint 合约"]
end
C --- C1
subgraph D_Details[ ]
D1["一次一个功能
Sprint 划分
Definition of Done"]
end
D --- D1
subgraph E_Details[ ]
E1["init.sh
context-reset
clean-state"]
end
E --- E1
style Harness fill:#e1f5ff
style A fill:#4dabf7,color:#fff
style B fill:#51cf66,color:#fff
style C fill:#fcc419
style D fill:#ff6b6b,color:#fff
style E fill:#a760ff,color:#fff
style A1 fill:#f8f9fa
style B1 fill:#f8f9fa
style C1 fill:#f8f9fa
style D1 fill:#f8f9fa
style E1 fill:#f8f9fa
Instructions(指令层)
- AGENTS.md(路由入口,约100行)
- ARCHITECTURE.md / QUALITY_SCORE.md / SECURITY.md / FRONTEND.md / PLANS.md
State(状态层)
- progress.md / feature_list.json
- git log / session-handoff.md
- 自动生成的 db-schema.md 等
Verification(验证层)
- 单元测试 / 类型检查 / Lint
- Playwright E2E(用户行为验证)
- Sprint 合约 / 评估量表
Scope(范围层)
- 一次一个功能 / Sprint 划分
- Definition of Done(完成定义)
Session Lifecycle(生命周期层)
- init.sh(启动阶段)
- context-reset / handoff(中间交接)
- clean-state checklist(结束阶段)
4. 仓库即唯一事实来源
这是 OpenAI 和 Anthropic 两篇文章最一致强调的原则:
“从 Agent 的角度来看,它在运行时无法在上下文中访问的任何内容都是不存在的。存储在 Google Docs、聊天记录或人们头脑中的知识都无法被系统访问。”
—— OpenAI 工程博客
知识编码的四个层次
- 层次 1:基础规范(持续有效):AGENTS.md / ARCHITECTURE.md / SECURITY.md
- 层次 2:当前状态(随项目演进):feature_list.json / progress.md / 自动生成的 db-schema.md
- 层次 3:执行计划(任务粒度):docs/exec-plans/active/ 和 docs/exec-plans/completed/
- 层次 4:参考文档(工具和库文档):docs/references/framework-llms.txt
知识腐烂防治
OpenAI 的实践中,有一个持续运行的”doc-gardening” Agent,专门扫描那些不再反映真实代码行为的过时文档,并自动发起修复 PR。同时有专门的 CI 作业验证知识库的更新状况、交叉链接和结构正确性。
5. 渐进式指令披露:从百科全书到路由器
5.1 单一大文件的四大失败原因
OpenAI 团队亲身验证了这一点:
- 上下文是稀缺资源:巨型文件挤掉了任务本身、相关代码和关键文档
- 过多指导反而无效:当一切都”重要”时,一切都不重要
- 立即腐烂:庞杂的手册变成陈旧规则的坟场,Agent 无法判断哪些信息仍然有效
- 难以验证:单一 blob 不适合机械检查(覆盖率、新鲜度、所有权、交叉链接)
5.2 文档路由模式
1 | AGENTS.md(约100行,作为目录) |
QUALITY_SCORE.md 是一个特别有价值的文档:它按产品域和架构层(A/B/C/D)追踪仓库随时间变强或变弱的趋势,让 Agent 能直接了解代码库的健康状态。
6. 多 Agent 架构:Generator-Evaluator 模式
Anthropic 从生成对抗网络(GAN)中获得灵感,设计了解决自我评估偏差的多 Agent 架构:
1 | 用户 prompt |
为什么需要独立的评估 Agent?
“将做工作的 Agent 与判断工作的 Agent 分离,证明是解决这一问题的强力手段。单独调优一个持怀疑态度的评估者,比让生成者批判自己的工作要容易得多。”
—— Anthropic 工程博客
关键是让评估 Agent 真实操作应用:评估 Agent 配备了 Playwright MCP,会像真实用户一样点击应用界面、测试 API、检查数据库状态,然后才给分。
7. Sprint 合约:在写代码之前就定义”完成”
Anthropic 实践中的重要创新:在每个 Sprint 开始前,Generator 和 Evaluator 必须就”完成”的具体含义达成共识。
sequenceDiagram
participant G as Generator
participant E as Evaluator
G->>E: 1. 提案:实现 X,标准 Y,验证 Z
E->>G: 2. 审查:需补充 W 验证
G->>E: 3. 修订方案
E->>G: 4. 达成一致
G->>G: 5. 开始实现(有合约约束)
E->>E: 6. 按合约标准验证
Note over G,E: 防止对"完成"有不同理解
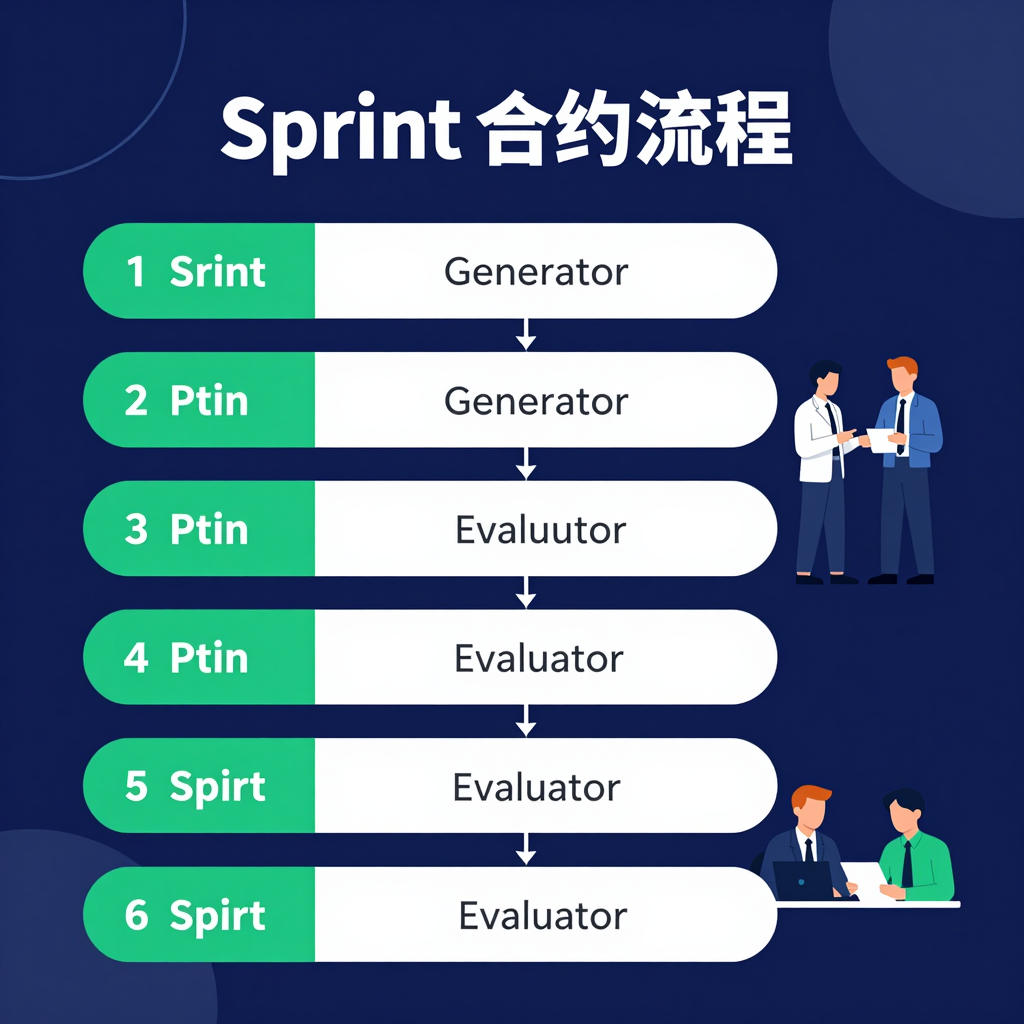
Sprint 合约协商流程:
- Generator 提案:”我将实现 X,成功标准是 Y,验证方式是 Z”
- Evaluator 审查:”你需要补充 W 的验证,否则我无法判断完成”
- 双方修订,直到达成一致
- Generator 开始实现(有合约约束)
- Evaluator 按合约标准验证
这一机制将产品规格(高层次)和可测试实现(底层细节)之间的鸿沟显式化,防止 Generator 和 Evaluator 对”完成”有不同理解。
8. 架构约束:让 Agent 在规则中高效工作
OpenAI 的经验:Agent 在有严格边界和可预测结构的环境中最为高效。
他们围绕严格的分层架构构建应用,每个业务域的依赖方向(只能”向前”):
graph LR
subgraph 依赖方向
A[Types
类型定义] --> B[Config
配置层]
B --> C[Repo
数据仓库]
C --> D[Service
业务逻辑]
D --> E[Runtime
运行时]
E --> F[UI
用户界面]
end
G[Providers
横切接口] -.-> A
G -.-> B
G -.-> C
G -.-> D
style A fill:#4dabf7,color:#fff
style B fill:#51cf66,color:#fff
style C fill:#fcc419
style D fill:#ff6b6b,color:#fff
style E fill:#a760ff,color:#fff
style F fill:#868e96,color:#fff
style G fill:#20c997,color:#fff
1 | Types → Config → Repo → Service → Runtime → UI |
这些约束通过自定义 Linter 和结构测试机械地强制执行(同样由 Agent 生成)。
“这种架构通常要等到拥有数百名工程师时才会推迟。对于编码 Agent 来说,这是一个早期的先决条件:有了约束,速度才不会下降,架构才不会漂移。”
自定义 Lint 规则的错误消息会在 Agent 上下文中注入修复指令,让 Agent 在违规时立即知道如何修复,而非只看到一条晦涩的错误。
9. 总结:Harness 的本质
mindmap root((Harness
Engineering)) 问题根源 上下文遗忘 验证差距 越界失控 五大子系统 Instructions State Verification Scope Session Lifecycle 核心价值 可靠性 可重复性 可维护性
| 问题类型 | Harness 的解法 | 来源 |
|---|---|---|
| 上下文遗忘 | 状态层(progress.md、feature_list) | GitHub 仓库 |
| 上下文焦虑 | 上下文重置 + 结构化交接 | Anthropic |
| 自我评估偏差 | Generator-Evaluator 分离 | Anthropic |
| 越界失控 | Scope 层(一次一个功能) | GitHub 仓库 |
| 指令腐烂 | 分层文档路由 | OpenAI |
| 知识不可见 | 仓库即事实来源 | OpenAI + Anthropic |
| 架构漂移 | 机械强制约束 + Linter | OpenAI |
| 验证不足 | Playwright E2E + Sprint 合约 | Anthropic |
模型提供能力(Capability),Harness 提供可靠性(Reliability)。随着模型越来越强,Harness 的有趣组合空间不会缩小——它只会移动。
下一篇实践篇将手把手带你用 4 个文件搭建第一个最小 Harness。
参考资料